Configuring Ollama Local Models
In the ever-evolving world of AI, running models locally can offer significant advantages in terms of privacy, speed, and customization. With Ollama—an open-source, ready-to-use tool—you can deploy powerful language models on your own machine, avoiding the recurring costs of commercial APIs. In this guide, we'll walk you through setting up Ollama, managing your local models with command line tools, and integrating them with PromptCue for seamless AI chat interactions.
What is Ollama?
Ollama is an open-source solution that lets you run language models locally or on your own server. It’s designed to streamline integration, allowing you to bypass expensive commercial APIs. With Ollama, you can take advantage of models like Meta’s Llama3.3—now available for commercial use—along with other local models optimized for various tasks.
- GitHub Repository: Ollama on GitHub
- Official Website: Ollama.com
Why Use Local AI Models with Ollama?
Local AI models provide several advantages:
- Enhanced Privacy:
Your data stays on your machine—no sensitive information is sent over the internet. - Faster Responses:
Eliminating network latency allows for near-instantaneous responses. - Customizability:
Tweak and optimize your models without being restricted by remote API limitations.
Ollama enables you to run powerful AI models locally, making it an ideal choice for users who value privacy and performance.
Configuring Ollama Local Models
1. Installation
-
Download Ollama:
Visit the Ollama website and download the installer for your operating system.
-
Follow Installation Instructions:
Run the installer and follow the on-screen instructions to complete the setup. Ensure your system meets the necessary hardware and software requirements.
Prefer running Ollama in a Docker container? Check out Ollama Docker documentation for easy, step-by-step setup instructions
2. Model Setup
Once installed, an Ollama icon should appear in your Windows taskbar (Windows OS)/Applications folder (MacOS).
If it doesn’t start automatically, search for “Ollama” in your Start menu and launch it.
-
Launch Ollama:
Open the Ollama application after installation. -
Select and Download Models:
Choose from a variety of available local models (e.g., Mistral, Mixtral, Gemma 2, LLaMA2, LLaMA3.3). Download the models you wish to use.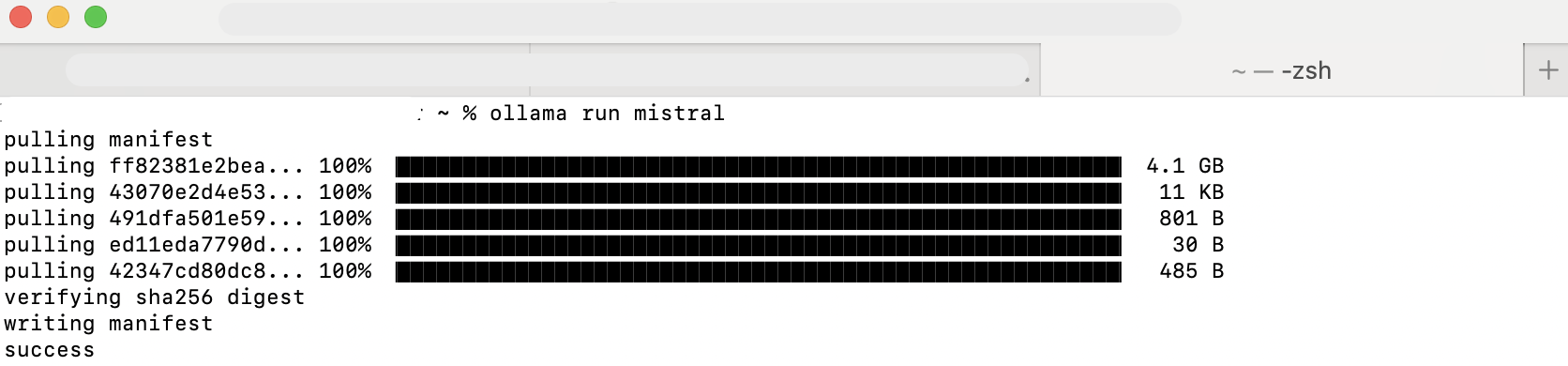
Downloading Mistral via Ollama -
Configure Model Settings:
Adjust settings such as memory allocation and processing limits to optimize performance for your selected models.
3. Running the Model Server
After installation and configuration, you need to start the local model server and manage your models using the command line.
-
Start the Server:
Once your models are configured, start the local model server within Ollama. -
Verify Operation:
Test the setup by entering a simple query using Ollama’s interface to ensure that the model responds correctly.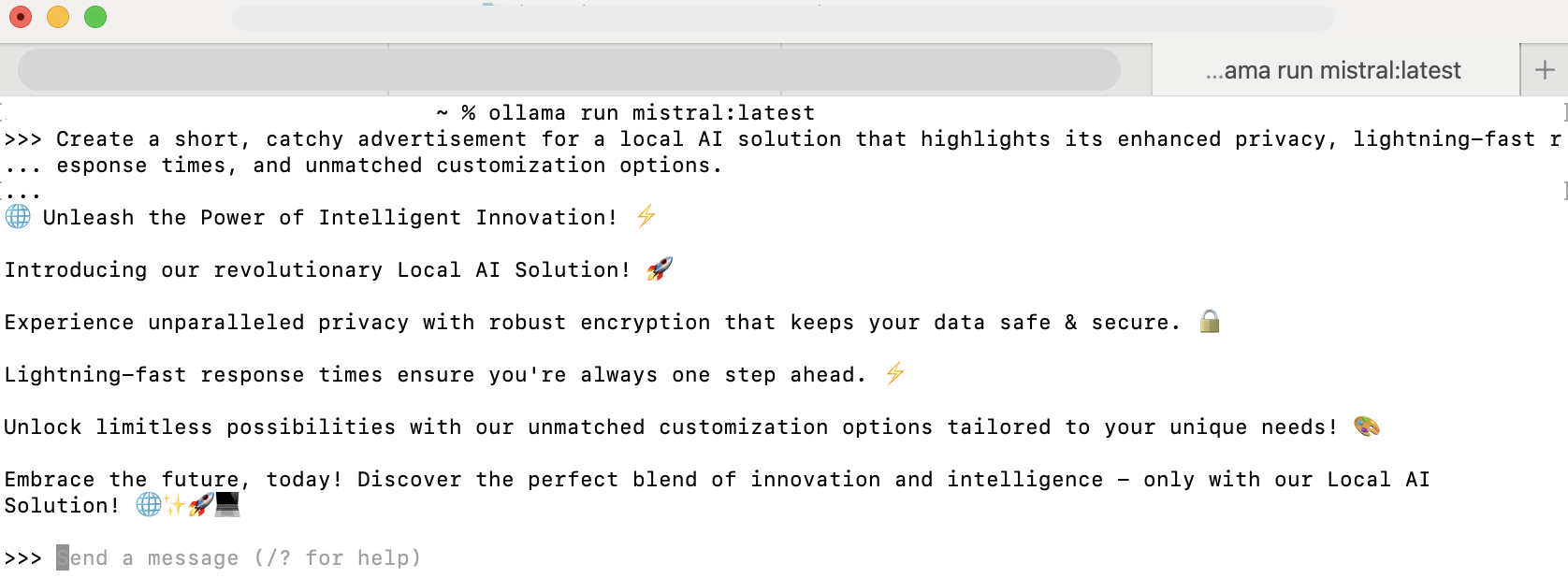
Sample Ollama Terminal Run
Key Commands via CMD/Terminal
Open your command prompt (CMD)/terminal and use the following commands:
- List Available Models:
ollama list - Check Model Details:
For example, to view details for the Llama3:3 model:
ollama show --modelfile llama3.3 - Remove a Model:
ollama rm llama3.3 - Serve Models:
Start serving your models with:
ollama serve
Downloading and Running Models Locally
Ollama offers a rich library of models available for download. Before pulling a model, ensure your system meets the hardware requirements—especially memory and, ideally, a GPU for smooth operation.
- Access the Model Library: Visit Ollama’s Library to browse available models.
- Download a Model:
For example, to pull the latest Llama3.3 model:
Or for a specific version (example 70b):
ollama pull llama3.3For multimodal models or specialized use-cases, check the provided instructions on the Ollama website.ollama pull llama3.3:70b
Integrating Ollama with PromptCue
Once your local models are up and running, you can integrate them with PromptCue.
1. Configuring the Connection
-
Navigate to PromptCue.
-
Ensure Ollama is running on your system.
Supported Ollama ModelsYou can checkout which Ollama models we support.
-
Select a Local Model:
In the model selection dropdown, choose the model running via Ollama. PromptCue will automatically:- Connect to your local Ollama server (using a
localhostconnection). - Verify that the AI model you selected is installed on your system.
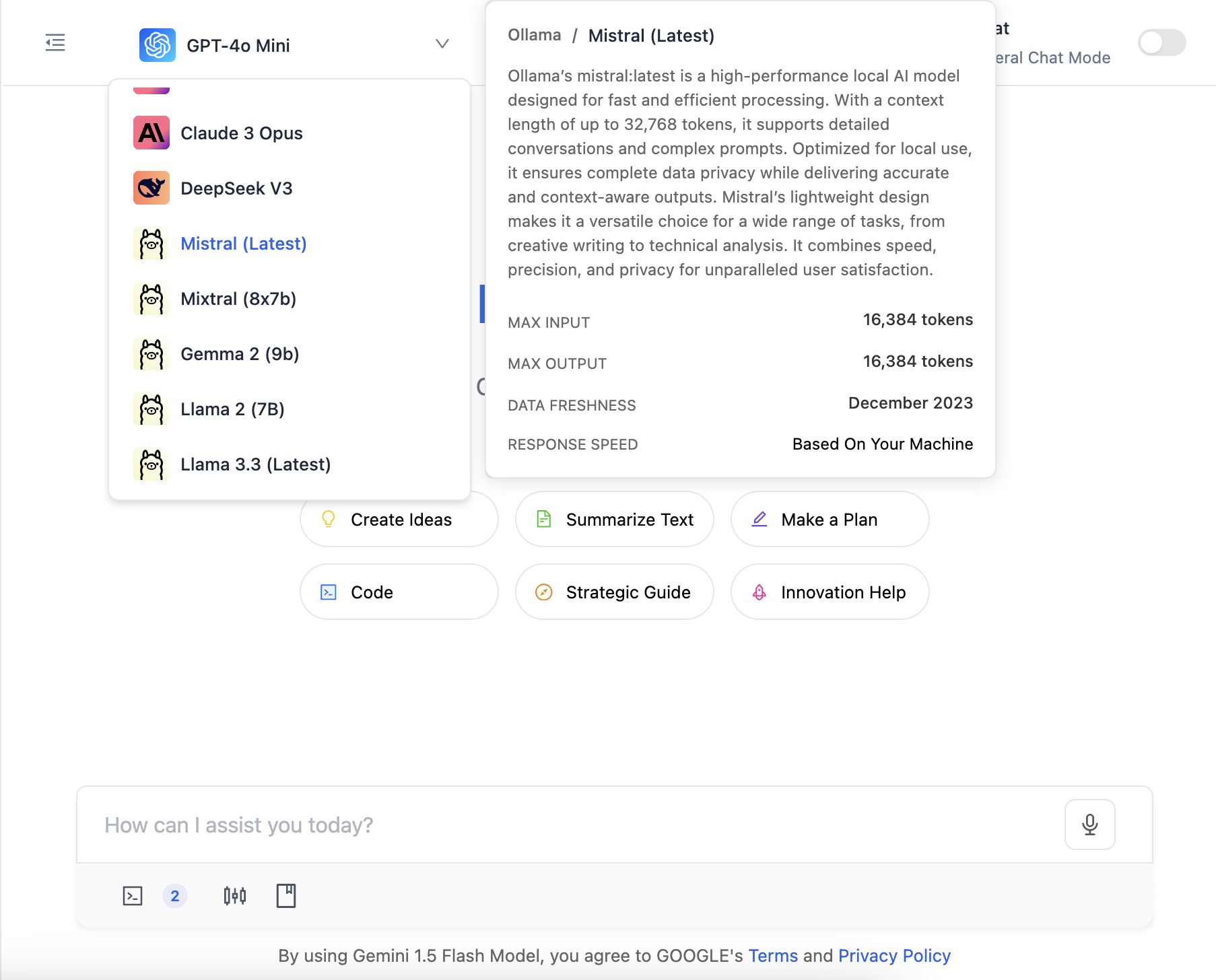
Model Selection ExampleFor instance, if you choose the 'Mistral (latest)' model, PromptCue will first establish a connection with your local Ollama and then check if the Mistral (latest) model is installed.
If either step fails, an error message will appear on the UI, clearly explaining the issue.
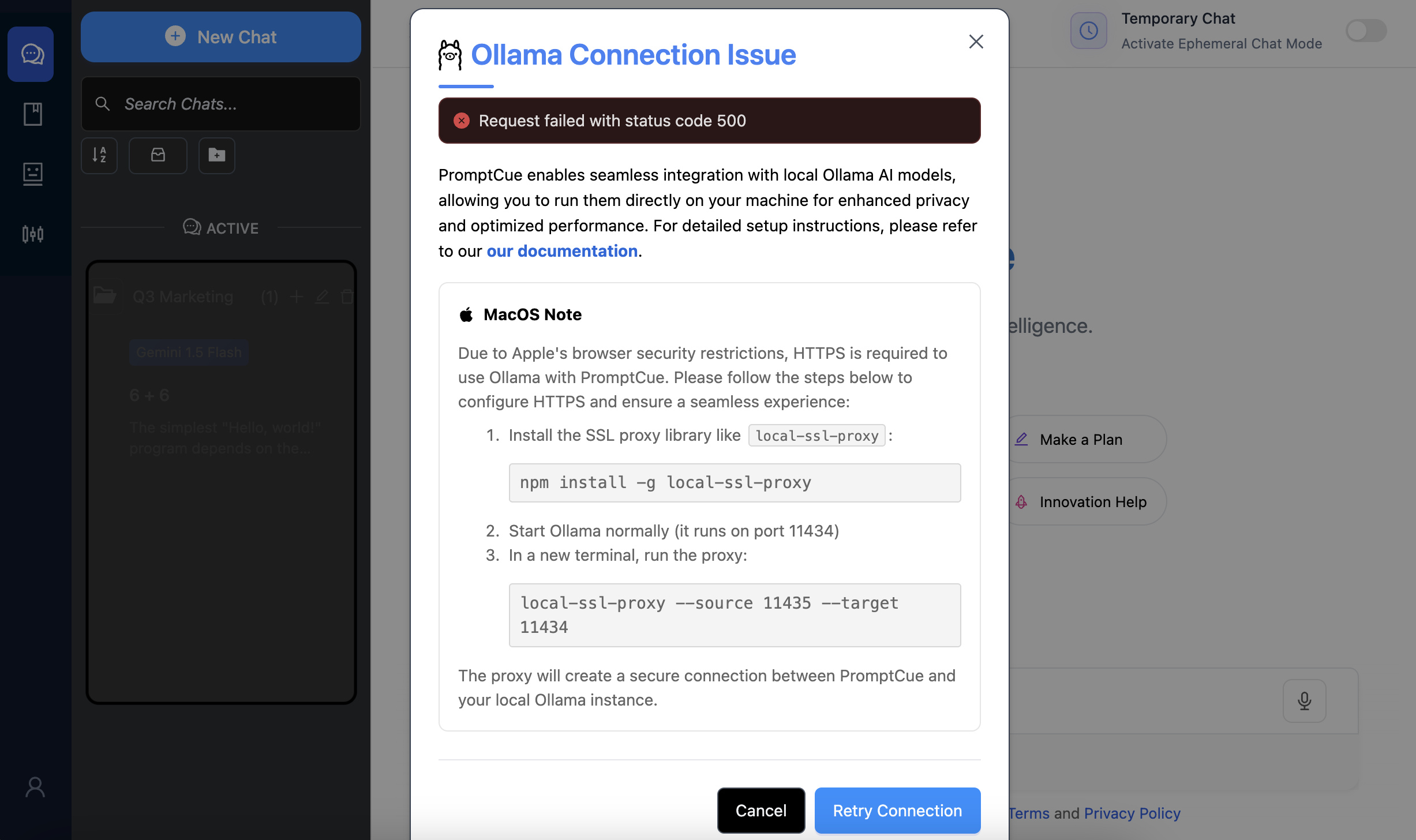
Unable To Connect Local Ollama 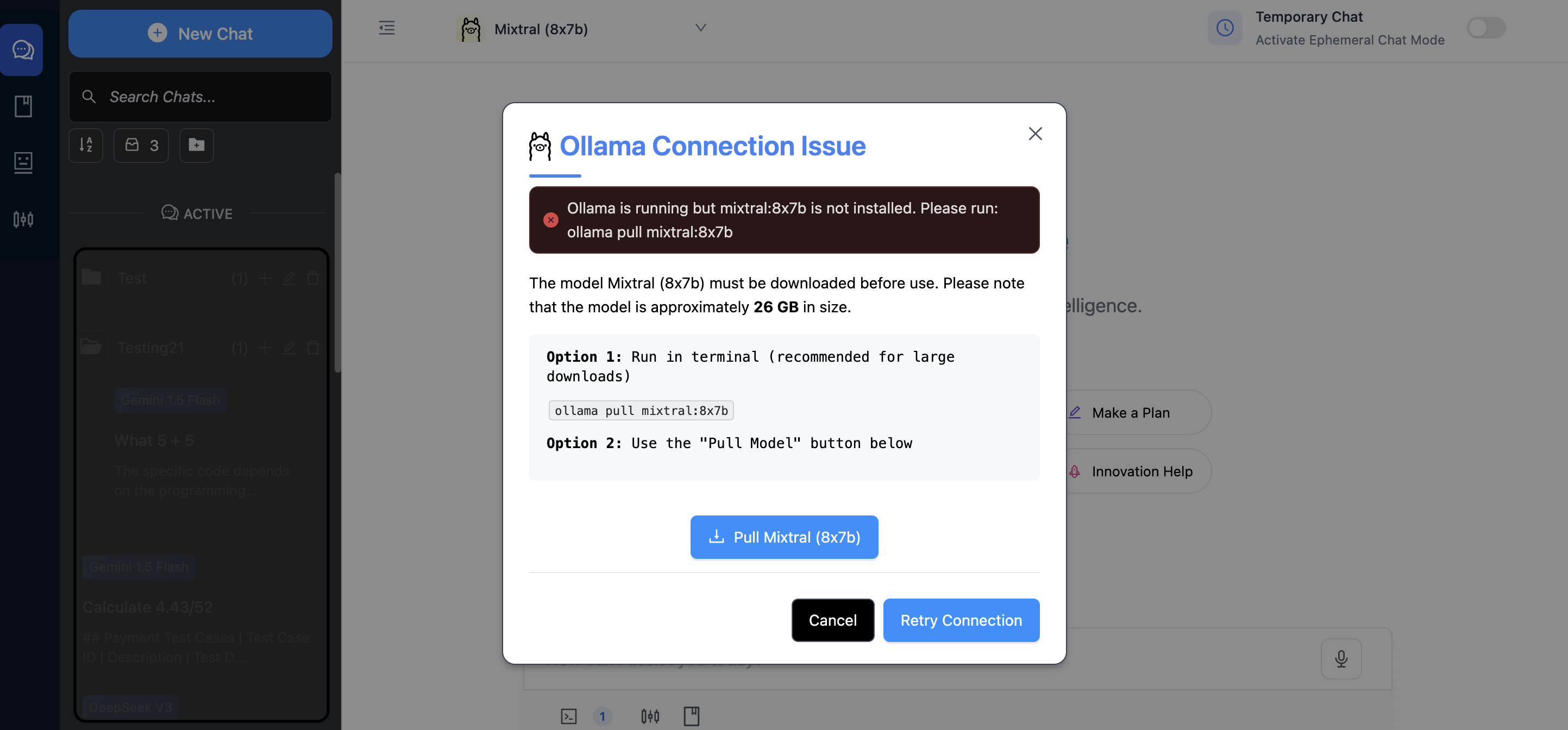
Local Ollama Connected But Model Not Present Apple security restrictionsDue to Apple's browser security restrictions, HTTPS is required to use Ollama with PromptCue. Please follow the steps below to configure HTTPS and ensure a seamless experience:
Install the SSL proxy library like
local-ssl-proxy:npm install -g local-ssl-proxy
- Start Ollama normally (it runs on port
11434) In a new terminal, run the proxy:
local-ssl-proxy --source 11435 --target 11434
The proxy will create a secure connection between PromptCue and your local Ollama instance.
- Connect to your local Ollama server (using a
-
No API Key Needed:
Because the model is hosted on your machine, you don’t need an API key—ensuring a secure, hassle-free experience.
2. Testing the Integration
PromptCue continuously monitors its connection to Ollama, ensuring you always stay linked to your local model for a seamless and reliable experience.
- Send a Test Prompt:
Type a simple query in PromptCue’s chatbox. Your prompt is forwarded to the local model, and a new response is generated. - Verify the Response:
The AI response should appear in your chat, confirming that the integration between Ollama and PromptCue is functioning correctly.
Since your Ollama model runs locally, its speed and performance depend on your computer's hardware configuration.
Benefits of Integrating Ollama with PromptCue
- Privacy & Security:
Local models keep your data private, as no information is transmitted to external servers. - Reduced Latency:
Enjoy faster responses as your queries are processed directly on your machine. - Customization:
Fine-tune your models to match your specific needs, ensuring optimal performance and flexibility. - Seamless Experience:
With automatic integration in PromptCue, switching between local and cloud-based models is effortless.
Conclusion
By configuring Ollama local models and integrating them with PromptCue, you can harness the full power of advanced AI while ensuring your data remains secure and your interactions stay fast. This setup is perfect for users who demand privacy, speed, and customizability.
Next Steps
- Deep Dive into Model Settings:
Explore our AI Model Settings documentation to learn more about fine-tuning your AI interactions. - Discover More Features:
Check out our other guides, such as Chatbox and Prompt Library, to maximize your experience. - Need Help?
Visit our Support & Resources page or contact us at support@promptcue.com for assistance.
Experience a smarter, faster, and more private AI interaction with PromptCue and Ollama—your journey to local AI excellence starts now!